Designing a Visual Orchestration Engine for Kubernetes: Inside KubeOrch Core
Most people look at a visual Kubernetes tool and assume the hard part is the drag-and-drop UI.
It isn’t.
Drawing boxes and arrows is easy. The real problem starts after that. Because once a user connects an API to Postgres, or a worker to Redis, or a frontend to a backend, the system now has to answer a much harder question: how do you turn that graph into infrastructure people can actually deploy and trust? That is the real problem KubeOrch Core is trying to solve.
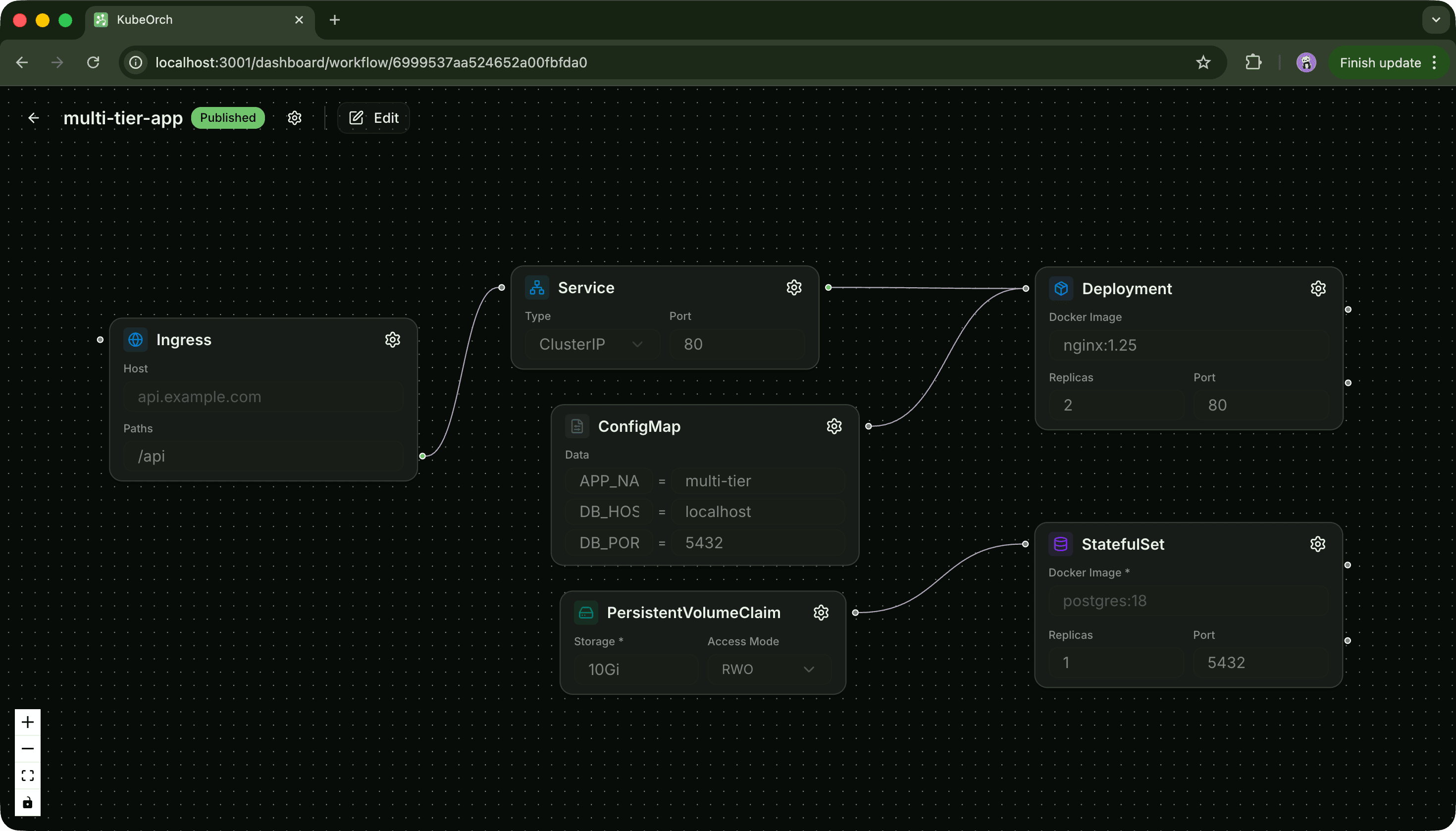
KubeOrch, at a high level, is a visual orchestration platform for Kubernetes. People see the canvas first, which makes sense. It is the most visible part of the product. But the interesting engineering work sits underneath it: the translation layer that takes a graph of services and connections and turns it into Kubernetes manifests, configs, secrets, and deployable topology.
A visual orchestrator is really a compiler

The easiest way to understand this kind of system is to stop thinking of it as a design tool. It is much closer to a compiler. The input is not code, but intent. A user places services on a canvas, connects them, configures them, and describes the shape of the system they want. The job of the core engine is to take that intent and compile it into concrete infrastructure.
That sounds neat in one sentence, but it gets complicated very quickly in practice. If a user draws: frontend → api → postgres that is not just a pretty diagram. That implies a whole chain of real infrastructure decisions. You need workloads. You need services. You need DNS and service discovery. You need environment variables. You need configuration handling. You probably need secret handling too. You need some sensible assumptions about what is public, what is internal, and what should be wired automatically versus exposed explicitly.
That is why the core matters so much. Anyone can build a canvas that lets users drag components around. The harder part is building a system that can look at that graph and say, “I know what this means operationally.” But most Kubernetes workflows force people to immediately translate that mental model into YAML, naming conventions, resource definitions, and low-level platform details. By the time you get to something deployable, the original system idea is buried under configuration. That mismatch is what made KubeOrch interesting to me in the first place.
The visual layer is not supposed to replace engineering. It is supposed to preserve the mental model long enough for the platform to generate the lower-level infrastructure correctly.
That is a very different goal from just “making Kubernetes easier.” The core starts with templates, not hardcoded cases One thing became obvious pretty early: if every component had to be special-cased in the engine, the whole thing would collapse. You can get away with that for a demo. You cannot get away with it for a real orchestration engine.
If Postgres has one path, Redis has another, RabbitMQ has another, MongoDB has another, and every new service adds more branching logic somewhere deep in the backend, the system becomes harder to extend every time you add a component. So the core has to be template-driven. That means the engine needs reusable definitions for how different classes of services should be rendered into infrastructure.
A service is not just a visual object on the canvas. It carries a deployment shape, configuration expectations, connectivity assumptions, and resource-generation rules. That abstraction matters a lot. Once the system is template-driven, adding a new kind of component becomes much more manageable. You are no longer stuffing one more exception into a giant orchestration switch statement. You are extending a model. That is the difference between building a feature and building a platform.
The interesting part is what a connection really means
This is where visual orchestration stops being a UI problem and becomes an engine design problem. On the canvas, a connection is just an edge. Inside the core, that edge carries meaning.
It is the system saying:
this service depends on that service
this dependency needs to be resolvable at runtime
this relationship should turn into infrastructure wiring
That usually means the engine has to synthesize actual deployment semantics from what looked like a simple line in the UI. A connection can imply internal addressing. It can imply generated environment variables. It can imply service discovery. It can imply dependency ordering. It can imply whether certain values should come from plain config or from secrets.
That is why I like the architecture diagram so much when explaining this system. It makes it obvious that the canvas is only the first layer. The real work happens in the path from graph state to orchestration logic to generated resources. That translation layer is the engine. And if it is not designed carefully, the whole system becomes either too magical or too fragile.
“Magic” is useful until it breaks trust
This is probably the hardest design tradeoff in a tool like this. A visual orchestrator should not force users to manually wire every single thing. If it does, the whole abstraction fails. But it also cannot become one of those systems that hides so much logic that users stop understanding what is happening underneath. That is where infrastructure tools get dangerous. If a platform silently makes a bunch of decisions for you and those decisions are wrong, you do not just get a weird UI bug. You get broken deployments, bad defaults, leaky abstractions, or security mistakes. So the question is never just “what can we automate?” The better question is:
what can we automate safely, consistently, and transparently enough that users can still build a correct mental model?
That is where a lot of the real product thinking in KubeOrch Core sits. Not every complexity should be exposed. But not every complexity should be hidden either. Some things should absolutely be inferred. Others should remain visible because they reflect real infrastructure constraints. That balance matters a lot more than people think. Security defaults are part of the productOne thing I feel strongly about is that a visual infra tool should not become “easy” by quietly becoming careless. There is a wrong way to simplify Kubernetes, and it usually looks like this: hide everything, wire everything automatically, and hope users never ask too many questions. That is fine for screenshots. It is terrible for trust. If a platform is generating real infrastructure, security defaults are part of the product. Things like separating config from secrets, avoiding unnecessary exposure, and making relationship wiring explicit enough to be understood are not optional details. They are central to whether people can rely on the system.
If you want to build in this space, KubeOrch/Core is open source, and I think this layer of infrastructure tooling still has a lot of room for new ideas.